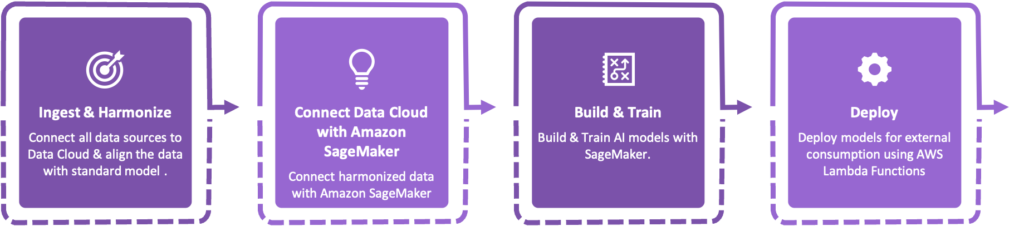
AI + Data + CRM is the talk of the town and it is all set to define future of business in the days to come. With so much AI + Data + CRM action in the Salesforce ecosystem, our team at Aethereus Studio also couldn’t wait to roll up their sleeves and experience it themselves. To test the waters, we selected customer churn prediction and cross sell recommendations as our use cases. The process of creating AI models using the shiny new setup of Data Cloud & SageMaker was really exciting for our team and in this article we have outlined how AI + Data + CRM can be brought to life in 4 simple steps:
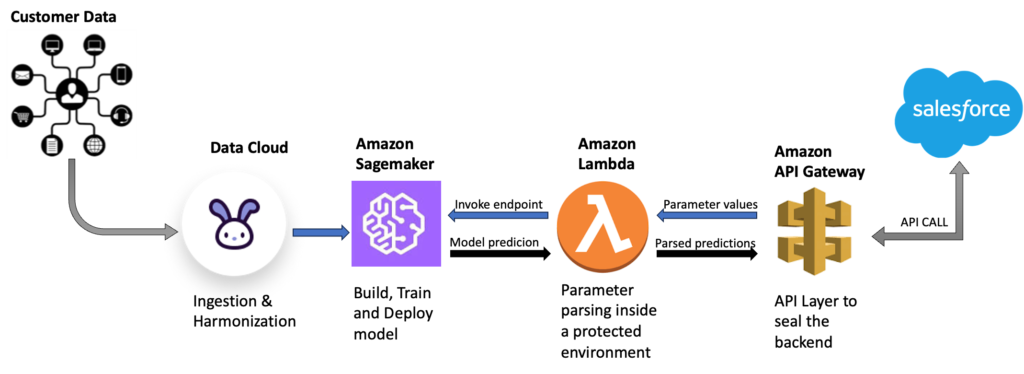
The below technical flow provides a high level setup of the components that were needed for carrying out the end to end process and can be used as a reference for building custom AI with Data Cloud. It is important to include the additional AWS components like Lambda Functions and API Gateway while defining the technical landscape as these are critical for making the models easy to consume.
Step 1 - Ingest & Harmonize Data in Data Cloud
The data we needed for AI modelling was gathered from multiple sources into Salesforce Data Cloud where the data was harmonized and synced with objects for consumption by the AI model. For our experiment, we imported customer’s sales data from Sales Cloud, browsing and web engagement data using Interaction Studio, customer’s complaints were imported from Service Cloud and purchase history was brought in from ERP data.

The data was imported into Data Cloud using Data Streams and Data Cloud Harmonization process was used to map the data elements to the standard and custom objects in Data cloud. We were now ready with more structured and unified data for use in the AI models.
Step 2 - Connect Data Cloud with Amazon SageMaker
While connecting Data Cloud with SageMaker you may encounter a road block inside Data Wrangler as the direct connector is available only in specific regions. So the best way to navigate around it is to improvise and proceed with another route that accesses data from Data Cloud using the Python salesforce-cdp-connector. This is a read-only Data Cloud client for Python and a connection is established with Data Cloud using a connected app inside Salesforce. After the connection was established, data was read with the help of a simple SOQL(Salesforce Object Query Language) query and stored inside a pandas dataframe.
Note: We created the above process by writing Python script inside a notebook instance of Amazon Sagemaker.
Step 3 - Build & Train model
Once we had the data inside a pandas dataframe, the process of data pre-processing was carried out. We covered two possible use cases when the processed data was ready for building & training the models:
- Cross Sell: Product recommendations based on the customer’s prior purchases, web engagement and browsing history
- Churn Prediction: Predicting the probability of a customer’s churn based on the customer’s data related to complaints, purchases, phone calls and engagement.
Use Case 1 – Cross Sell
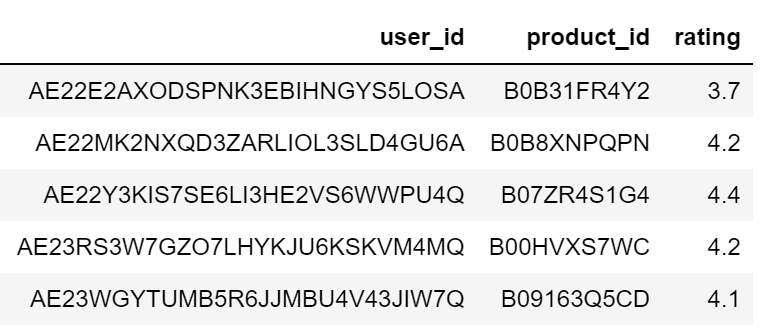
Our cross-sell model dataset consisted of the following columns: product_id (unique identification for each product), user_id (unique identification for each customer), and rating (out of 5) which told how much the user liked the product.
To recommend customers products that they might be interested in, a collaborative filtering approach with clustering was used. Our approach was as follows:
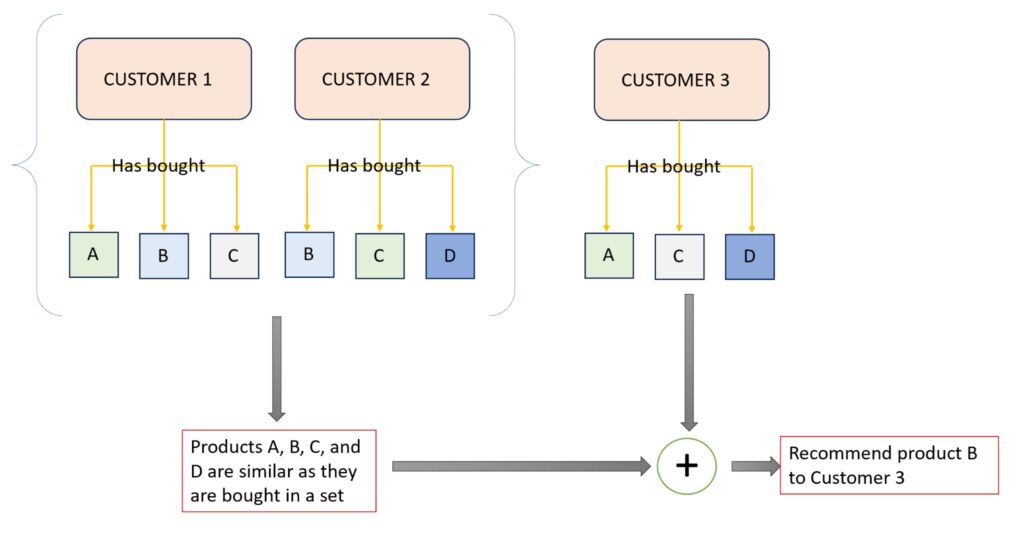
If customer 1 has bought products A, B and C; and customer 2 has bought products A and B, then it is likely that customer 2 will also buy product C (also explained in the diagram below). For this, we needed to find products close to each other. This can be done by dividing the dataset into clusters and assigning products to each of those clusters.
To make the dataset usable, it was transposed into a matrix with rows denoting products and columns denoting customers. The value of a cell is equal to the rating that the product has received from a customer else it is 0.
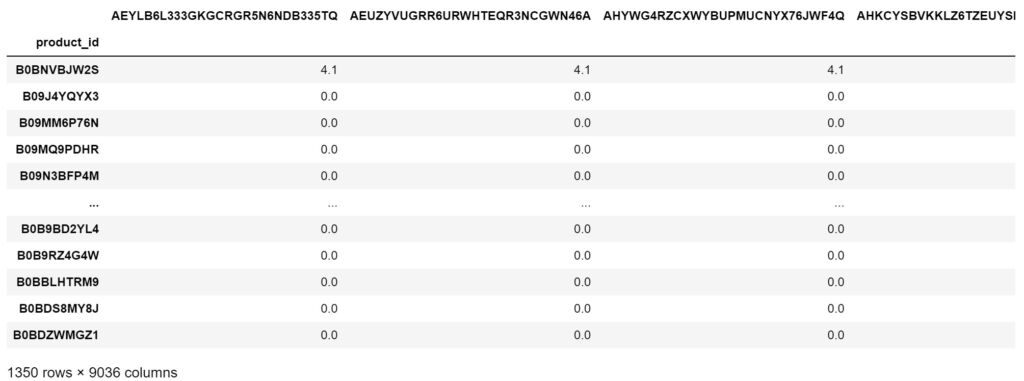
Below is a scatter plot of the number of products that are rated by each user:
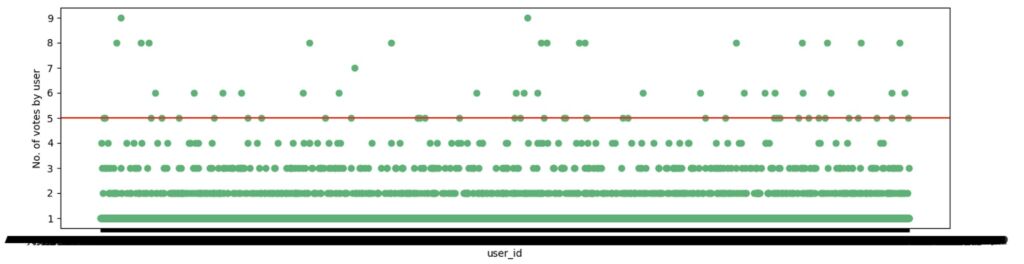
Most of the users had rated either one or two products only. This is because our dataset contained the ratings of only a single year.
Sagemaker has a plethora of built-in models that can be used for machine learning / AI and for this use case, the KMeans model was used and deployed to an endpoint.
Use Case 2 – Churn Prediction
Churn prediction is one of the most important parameters for any organization. Organizations need to understand how many of their customers stay with them and how many will leave. This helps organizations understand the areas of improvement and prevent their customers from leaving.
To build the machine learning model, we used the in-built xgboost algorithm that comes with Sagemaker out of the box. Some of the hyperparameters were defined which were specific to the model we were building. Once we had our model and parameters in place we started the training. After training the model, it was stored in the output path previously defined and the model was saved as a tar.gz file.
Step 4 - Deploy the models
In this step we deployed the SageMaker model to an external API that can be consumed by Salesforce CRM or any application using REST protocol.
The model deployment process involved deployment of the SageMaker models to an endpoint, the created endpoint was then called in Amazon Lambda which contained a single function. The purpose of the function is to take a JSON containing the customer’s data as input and returns the recommended product as a JSON. While the outputs are input and outputs are JSON, the lambda function transforms the request to a model acceptable format and then formats the output back to JSON.
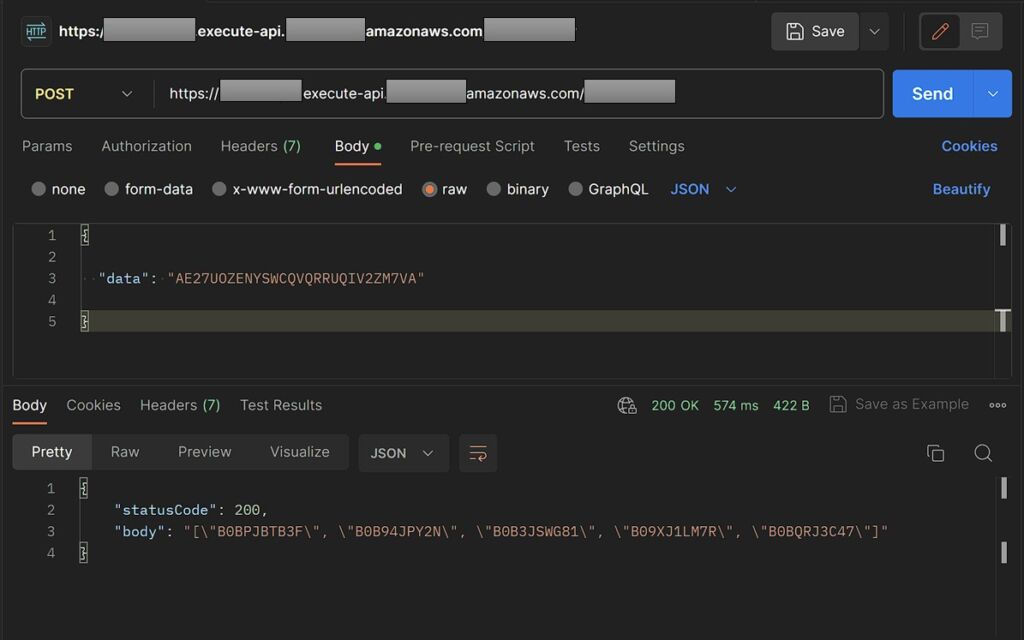
To expose this function to Salesforce CRM and other external apps, a REST API was created in Amazon API Gateway, which was integrated with the lambda function created above. Below are sample outputs for the corss-sell & churn models:
Output – Cross Sell Recommendations
After the endpoint was deployed, it was possible to obtain the closest cluster of each product and its distance from the cluster by invoking the endpoint. The result looks as follows:
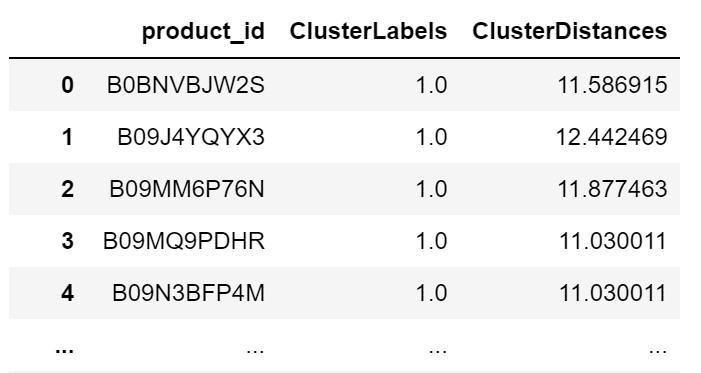
We then grouped this table by cluster number and sorted it by distance. This enabled us to create a function that takes product_id as input and produced an output of other products in the same cluster and thereby leading to a list of recommended products for the customer.
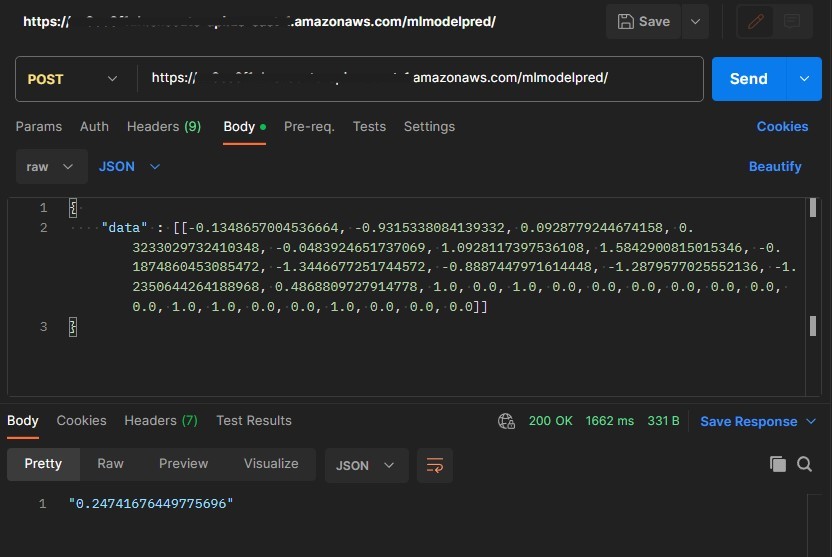
Output – Churn Probability
Once we deployed the model, an endpoint was created, customer attributes were passed to the model through an API call and it returned the probability of customer’s churn.
Conclusion
The process of building an AI model with Data Cloud and SageMaker brought in a lot simplicity and advantages when compared to the traditional machine learning & AI process:
- The quality of input data was much better as the data from multiple sources could be combined and pre-processed easily in Data Cloud.
- Data was seamlessly available in SageMaker using standard libraries for model creation and training.
- The model creation & deployment process were accelerated with pre-built models and tools available in SageMaker
- With the bring your own model framework we were able to develop highly personalized recommendations very quickly thanks to the Customer 360 data in Data Cloud.
As we were building our 2 uses cases and dived deeper, the team was able to come up with a number of other creative industry use cases that are going to be built next using the power of AI + Data + CRM. While we are at it, if you have any exciting AI use cases that you want to try out for your organization and are looking for help on how to use AI + Data + CRM to create magic for your users then reach out to us on our website or LinkedIn page.